Jupyter Snippet PDSH 02.07-Fancy-Indexing
Jupyter Snippet PDSH 02.07-Fancy-Indexing
This notebook contains an excerpt from the Python Data Science Handbook by Jake VanderPlas; the content is available on GitHub.
The text is released under the CC-BY-NC-ND license, and code is released under the MIT license. If you find this content useful, please consider supporting the work by buying the book!
< Comparisons, Masks, and Boolean Logic | Contents | Sorting Arrays >
Fancy Indexing
In the previous sections, we saw how to access and modify portions of arrays using simple indices (e.g., arr[0]), slices (e.g., arr[:5]), and Boolean masks (e.g., arr[arr > 0]).
In this section, we’ll look at another style of array indexing, known as fancy indexing.
Fancy indexing is like the simple indexing we’ve already seen, but we pass arrays of indices in place of single scalars.
This allows us to very quickly access and modify complicated subsets of an array’s values.
Exploring Fancy Indexing
Fancy indexing is conceptually simple: it means passing an array of indices to access multiple array elements at once. For example, consider the following array:
import numpy as np
rand = np.random.RandomState(42)
x = rand.randint(100, size=10)
print(x)
[51 92 14 71 60 20 82 86 74 74]
Suppose we want to access three different elements. We could do it like this:
[x[3], x[7], x[2]]
[71, 86, 14]
Alternatively, we can pass a single list or array of indices to obtain the same result:
ind = [3, 7, 4]
x[ind]
array([71, 86, 60])
When using fancy indexing, the shape of the result reflects the shape of the index arrays rather than the shape of the array being indexed:
ind = np.array([[3, 7],
[4, 5]])
x[ind]
array([[71, 86],
[60, 20]])
Fancy indexing also works in multiple dimensions. Consider the following array:
X = np.arange(12).reshape((3, 4))
X
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
Like with standard indexing, the first index refers to the row, and the second to the column:
row = np.array([0, 1, 2])
col = np.array([2, 1, 3])
X[row, col]
array([ 2, 5, 11])
Notice that the first value in the result is X[0, 2], the second is X[1, 1], and the third is X[2, 3].
The pairing of indices in fancy indexing follows all the broadcasting rules that were mentioned in Computation on Arrays: Broadcasting.
So, for example, if we combine a column vector and a row vector within the indices, we get a two-dimensional result:
X[row[:, np.newaxis], col]
array([[ 2, 1, 3],
[ 6, 5, 7],
[10, 9, 11]])
Here, each row value is matched with each column vector, exactly as we saw in broadcasting of arithmetic operations. For example:
row[:, np.newaxis] * col
array([[0, 0, 0],
[2, 1, 3],
[4, 2, 6]])
It is always important to remember with fancy indexing that the return value reflects the broadcasted shape of the indices, rather than the shape of the array being indexed.
Combined Indexing
For even more powerful operations, fancy indexing can be combined with the other indexing schemes we’ve seen:
print(X)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
We can combine fancy and simple indices:
X[2, [2, 0, 1]]
array([10, 8, 9])
We can also combine fancy indexing with slicing:
X[1:, [2, 0, 1]]
array([[ 6, 4, 5],
[10, 8, 9]])
And we can combine fancy indexing with masking:
mask = np.array([1, 0, 1, 0], dtype=bool)
X[row[:, np.newaxis], mask]
array([[ 0, 2],
[ 4, 6],
[ 8, 10]])
All of these indexing options combined lead to a very flexible set of operations for accessing and modifying array values.
Example: Selecting Random Points
One common use of fancy indexing is the selection of subsets of rows from a matrix. For example, we might have an $N$ by $D$ matrix representing $N$ points in $D$ dimensions, such as the following points drawn from a two-dimensional normal distribution:
mean = [0, 0]
cov = [[1, 2],
[2, 5]]
X = rand.multivariate_normal(mean, cov, 100)
X.shape
(100, 2)
Using the plotting tools we will discuss in Introduction to Matplotlib, we can visualize these points as a scatter-plot:
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn; seaborn.set() # for plot styling
plt.scatter(X[:, 0], X[:, 1]);
Let’s use fancy indexing to select 20 random points. We’ll do this by first choosing 20 random indices with no repeats, and use these indices to select a portion of the original array:
indices = np.random.choice(X.shape[0], 20, replace=False)
indices
array([93, 45, 73, 81, 50, 10, 98, 94, 4, 64, 65, 89, 47, 84, 82, 80, 25,
90, 63, 20])
selection = X[indices] # fancy indexing here
selection.shape
(20, 2)
Now to see which points were selected, let’s over-plot large circles at the locations of the selected points:
plt.scatter(X[:, 0], X[:, 1], alpha=0.3)
plt.scatter(selection[:, 0], selection[:, 1],
facecolor='none', s=200);
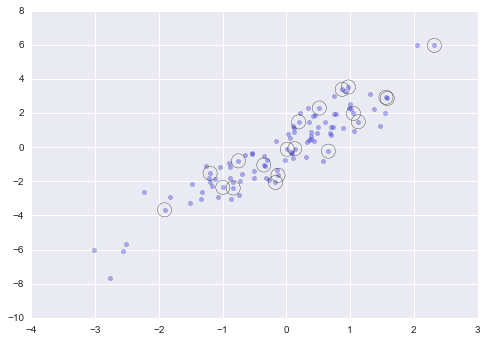
This sort of strategy is often used to quickly partition datasets, as is often needed in train/test splitting for validation of statistical models (see Hyperparameters and Model Validation), and in sampling approaches to answering statistical questions.
Modifying Values with Fancy Indexing
Just as fancy indexing can be used to access parts of an array, it can also be used to modify parts of an array. For example, imagine we have an array of indices and we’d like to set the corresponding items in an array to some value:
x = np.arange(10)
i = np.array([2, 1, 8, 4])
x[i] = 99
print(x)
[ 0 99 99 3 99 5 6 7 99 9]
We can use any assignment-type operator for this. For example:
x[i] -= 10
print(x)
[ 0 89 89 3 89 5 6 7 89 9]
Notice, though, that repeated indices with these operations can cause some potentially unexpected results. Consider the following:
x = np.zeros(10)
x[[0, 0]] = [4, 6]
print(x)
[ 6. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
Where did the 4 go? The result of this operation is to first assign x[0] = 4, followed by x[0] = 6.
The result, of course, is that x[0] contains the value 6.
Fair enough, but consider this operation:
i = [2, 3, 3, 4, 4, 4]
x[i] += 1
x
array([ 6., 0., 1., 1., 1., 0., 0., 0., 0., 0.])
You might expect that x[3] would contain the value 2, and x[4] would contain the value 3, as this is how many times each index is repeated. Why is this not the case?
Conceptually, this is because x[i] += 1 is meant as a shorthand of x[i] = x[i] + 1. x[i] + 1 is evaluated, and then the result is assigned to the indices in x.
With this in mind, it is not the augmentation that happens multiple times, but the assignment, which leads to the rather nonintuitive results.
So what if you want the other behavior where the operation is repeated? For this, you can use the at() method of ufuncs (available since NumPy 1.8), and do the following:
x = np.zeros(10)
np.add.at(x, i, 1)
print(x)
[ 0. 0. 1. 2. 3. 0. 0. 0. 0. 0.]
The at() method does an in-place application of the given operator at the specified indices (here, i) with the specified value (here, 1).
Another method that is similar in spirit is the reduceat() method of ufuncs, which you can read about in the NumPy documentation.
Example: Binning Data
You can use these ideas to efficiently bin data to create a histogram by hand.
For example, imagine we have 1,000 values and would like to quickly find where they fall within an array of bins.
We could compute it using ufunc.at like this:
np.random.seed(42)
x = np.random.randn(100)
# compute a histogram by hand
bins = np.linspace(-5, 5, 20)
counts = np.zeros_like(bins)
# find the appropriate bin for each x
i = np.searchsorted(bins, x)
# add 1 to each of these bins
np.add.at(counts, i, 1)
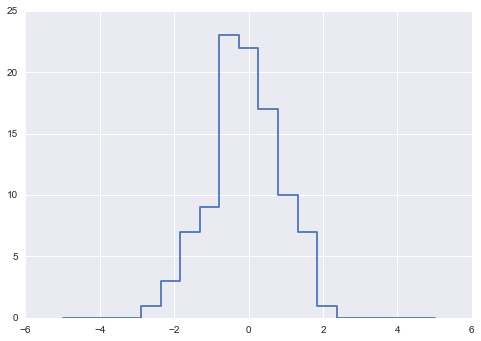
The counts now reflect the number of points within each bin–in other words, a histogram:
# plot the results
plt.plot(bins, counts, linestyle='steps');
Of course, it would be silly to have to do this each time you want to plot a histogram.
This is why Matplotlib provides the plt.hist() routine, which does the same in a single line:
plt.hist(x, bins, histtype='step');
This function will create a nearly identical plot to the one seen here.
To compute the binning, matplotlib uses the np.histogram function, which does a very similar computation to what we did before. Let’s compare the two here:
print("NumPy routine:")
%timeit counts, edges = np.histogram(x, bins)
print("Custom routine:")
%timeit np.add.at(counts, np.searchsorted(bins, x), 1)
NumPy routine:
10000 loops, best of 3: 97.6 µs per loop
Custom routine:
10000 loops, best of 3: 19.5 µs per loop
Our own one-line algorithm is several times faster than the optimized algorithm in NumPy! How can this be?
If you dig into the np.histogram source code (you can do this in IPython by typing np.histogram??), you’ll see that it’s quite a bit more involved than the simple search-and-count that we’ve done; this is because NumPy’s algorithm is more flexible, and particularly is designed for better performance when the number of data points becomes large:
x = np.random.randn(1000000)
print("NumPy routine:")
%timeit counts, edges = np.histogram(x, bins)
print("Custom routine:")
%timeit np.add.at(counts, np.searchsorted(bins, x), 1)
NumPy routine:
10 loops, best of 3: 68.7 ms per loop
Custom routine:
10 loops, best of 3: 135 ms per loop
What this comparison shows is that algorithmic efficiency is almost never a simple question. An algorithm efficient for large datasets will not always be the best choice for small datasets, and vice versa (see Big-O Notation).
But the advantage of coding this algorithm yourself is that with an understanding of these basic methods, you could use these building blocks to extend this to do some very interesting custom behaviors.
The key to efficiently using Python in data-intensive applications is knowing about general convenience routines like np.histogram and when they’re appropriate, but also knowing how to make use of lower-level functionality when you need more pointed behavior.
< Comparisons, Masks, and Boolean Logic | Contents | Sorting Arrays >